A two-day workshop, with both technical hands-on and idea-driven components. Learn to scrape data and reuse public and private information by writing custom code and using the Facebook API. Additionally, we’ll converse and conceptualize ideas to reclaim our data literally and also imagine what is possible with our data once it is ours!
Here are the slides and some of the code samples from the Freedom for Our Files (FFOF) workshop I just did in Linz at Art Meets Radical Openness (LiWoLi 2011).
The first one is a basic scraping demo that uses “find-replace” parsing to change specific words (I’m including examples below the code)<?php
/* Basic scraping demo with "find-replace" parsing
* Owen Mundy Copyright 2011 GNU/GPL */
$url = "http://www.bbc.co.uk/news/"; // 0. url to start with
$contents = file_get_contents($url); // 1. get contents of page in a string
// 2. search and replace contents
$contents = str_replace( // str_replace(search, replace, string)
"News",
"<b style='background:yellow; color:#000; padding:2px'>LIES</b>",
$contents);
print $contents; // 3. print result
?>
Basic scraping demo with “foreach” parsing<?php
/* Basic scraping demo with "foreach" parsing
* Owen Mundy Copyright 2011 GNU/GPL */
$url = "http://www.bbc.co.uk/news/"; // 0. url to start with
$lines = file($url); // 1. get contents of url in an array
foreach ($lines as $line_num => $line) // 2. loop through each line in page
{
// 3. if opening string is found
if(strpos($line, '<h2 class="top-story-header ">'))
{
$get_content = true; // 4. we can start getting content
}
if($get_content == true)
{
$data .= $line . "\n"; // 5. then store content until closing string appears
}
if(strpos($line, "</h2>")) // 6. if closing HTML element found
{
$get_content = false; // 7. stop getting content
}
}
print $data; // 8. print result
?>
Basic scraping demo with “regex” parsing<?php
/* Basic scraping demo with "regex" parsing
* Owen Mundy Copyright 2011 GNU/GPL */
$url = "http://www.bbc.co.uk/news/"; // 0. url to start with
$contents = file_get_contents($url); // 1. get contents of url in a string
// 2. match title
preg_match('/<title>(.*)<\/title>/i', $contents, $title);
print $title[1]; // 3. print result
?>
Basic scraping demo with “foreach” and “regex” parsing<?php
/* Basic scraping demo with "foreach" and "regex" parsing
* Owen Mundy Copyright 2011 GNU/GPL */
// url to start
$url = "http://www.bbc.co.uk/news/";
// get contents of url in an array
$lines = file($url);
// look for the string
foreach ($lines as $line_num => $line)
{
// find opening string
if(strpos($line, '<h2 class="top-story-header ">'))
{
$get_content = true;
}
// if opening string is found
// then print content until closing string appears
if($get_content == true)
{
$data .= $line . "\n";
}
// closing string
if(strpos($line, "</h2>"))
{
$get_content = false;
}
}
// use regular expressions to extract only what we need...
// png, jpg, or gif inside a src="..." or src='...'
$pattern = "/src=[\"']?([^\"']?.*(png|jpg|gif))[\"']?/i";
preg_match_all($pattern, $data, $images);
// text from link
$pattern = "/(<a.*>)(\w.*)(<.*>)/ismU";
preg_match_all($pattern, $data, $text);
// link
$pattern = "/(href=[\"'])(.*?)([\"'])/i";
preg_match_all($pattern, $data, $link);
/*
// test if you like
print "<pre>";
print_r($images);
print_r($text);
print_r($link);
print "</pre>";
*/
?>
<html>
<head>
<style>
body { margin:0; }
.textblock { position:absolute; top:600px; left:0px; }
span { font:5.0em/1.0em Arial, Helvetica, sans-serif; line-height:normal;
background:url(trans.png); color:#fff; font-weight:bold; padding:5px }
a { text-decoration:none; color:#900 }
</style>
</head>
<body>
<img src="<?php print $images[1][0] ?>" height="100%"> </div>
<div class="textblock"><span><a href="<?php print "http://www.bbc.co.uk".$link[2][0] ?>"><?php print $text[2][0] ?></a></span><br>
</div>
</body>
</html>
And the example, which presents the same information in a new way…
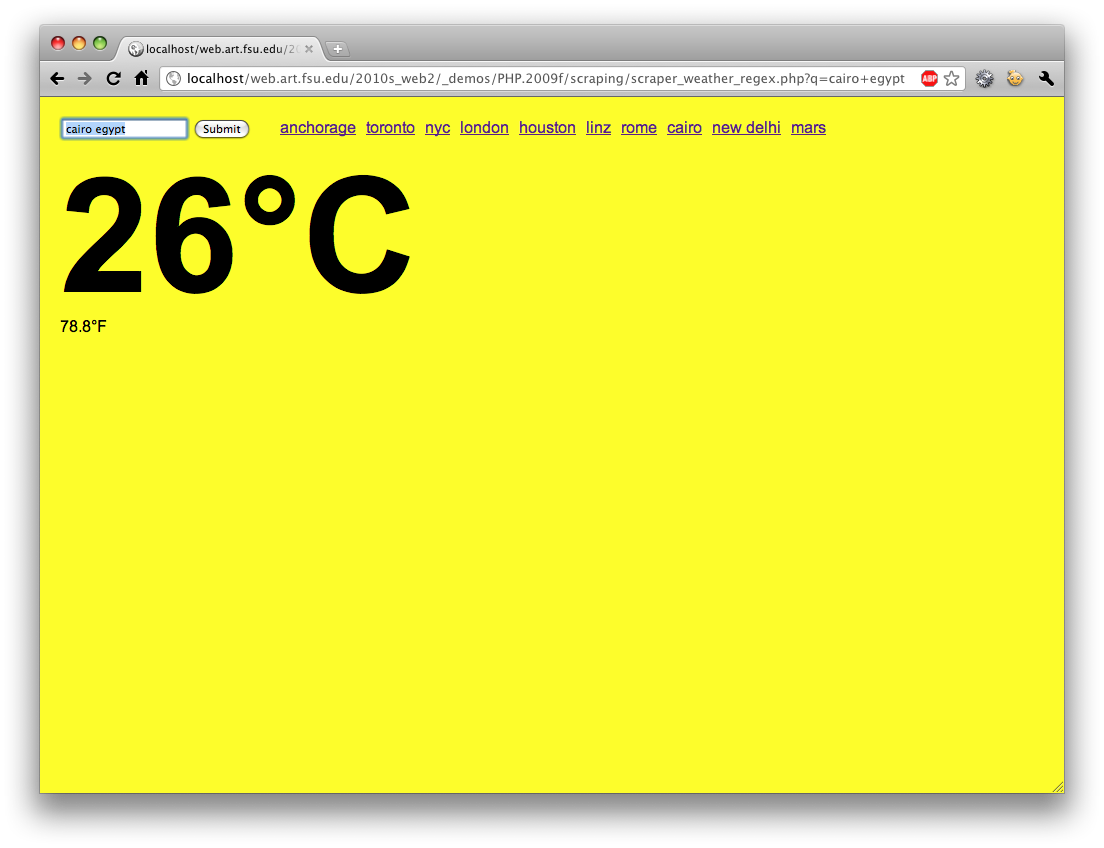
Advanced scraping demo with “regex” parsing. Retrieves current weather in any city and colors the background accordingly. The math below for normalization could use some work.<?php
/* Advanced scraping demo with "regex" parsing. Retrieves current
* weather in any city and colors the background accordingly.
* The math below for normalization could use some work.
* Owen Mundy Copyright 2011 GNU/GPL */
?>
<html>
<head>
<style>
body { margin:20; font:1.0em/1.4em Arial, Helvetica, sans-serif; }
.text { font:10.0em/1.0em Arial, Helvetica, sans-serif; color:#000; font-weight:bold; }
.navlist { list-style:none; margin:0; position:absolute; top:20px; left:200px }
.navlist li { float:left; margin-right:10px; }
</style>
</head>
<body onLoad="document.f.q.focus();">
<form method="GET" action="<?php print $_SERVER['PHP_SELF']; ?>" name="f">
<input type="text" name="q" value="<?php print $_GET['q'] ?>" />
<input type="submit" />
</form>
<ul class="navlist">
<li><a href="?q=anchorage+alaska">anchorage</a></li>
<li><a href="?q=toronto+canada">toronto</a></li>
<li><a href="?q=new+york+ny">nyc</a></li>
<li><a href="?q=london+uk">london</a></li>
<li><a href="?q=houston+texas">houston</a></li>
<li><a href="?q=linz+austria">linz</a></li>
<li><a href="?q=rome+italy">rome</a></li>
<li><a href="?q=cairo+egypt">cairo</a></li>
<li><a href="?q=new+delhi+india">new delhi</a></li>
<li><a href="?q=mars">mars</a></li>
</ul>
<?php
// make sure the form has been sent
if (isset($_GET['q']))
{
// get contents of url in an array
if ($str = file_get_contents('http://www.google.com/search?q=weather+in+'
. str_replace(" ","+",$_GET['q'])))
{
// use regular expressions to extract only what we need...
// 1, 2, or 3 digits followed by any version of the degree symbol
$pattern = "/[0-9]{1,3}[º°]C/";
// match the pattern with a C or with an F
if (preg_match_all($pattern, $str, $data) > 0)
{
$scale = "C";
}
else
{
$pattern = "/[0-9]{1,3}[º°]F/";
if (preg_match_all($pattern, $str, $data) > 0)
{
$scale = "F";
}
}
// remove html
$temp_str = strip_tags($data[0][0]);
// remove everything except numbers and points
$temp = ereg_replace("[^0-9..]", "", $temp_str);
if ($temp)
{
// what is the scale?
if ($scale == "C"){
// convert ºC to ºF
$tempc = $temp;
$tempf = ($temp*1.8)+32;
}
else if ($scale == "F")
{
// convert ºF to ºC
$tempc = ($temp-32)/1.8;
$tempf = $temp;
}
// normalize the number
$color = round($tempf/140,1)*10;
// cool -> warm
// scale -20 to: 120
$color_scale = array(
'0, 0,255',
'0,128,255',
'0,255,255',
'0,255,128',
'0,255,0',
'128,255,0',
'255,255,0',
'255,128,0',
'255, 0,0'
);
?>
<style> body { background:rgb(<?php print $color_scale[$color] ?>) }</style>
<div class="text"><?php print round($tempc,1) ."°C " ?></div>
<?php print round($tempf,1) ?>°F
<?php
}
else
{
print "city not found";
}
}
}
?>
</body>
</html>
For an xpath tutorial check this page .
For the next part of the workshop we used Give Me My Data to export our information from Facebook in order to revisualize it with Nodebox 1.0 , a Python IDE similar to Processing.org. Here’s an example:
Update: Some user images from the workshop. Thanks all who joined!
Mutual friends (using Give Me My Data and Graphviz) by Rob Canning
identi.ca network output (starting from my username (claude) with depth 5, rendered to svg with ‘sfdp’ from graphviz) by Claude Heiland-Allen