A two-day workshop, with both technical hands-on and idea-driven components. Learn to scrape data and reuse public and private information by writing custom code and using the Facebook API. Additionally, we’ll converse and conceptualize ideas to reclaim our data literally and also imagine what is possible with our data once it is ours!
Here are the slides and some of the code samples from the Freedom for Our Files (FFOF) workshop I just did in Linz at Art Meets Radical Openness (LiWoLi 2011).
The first one is a basic scraping demo that uses “find-replace” parsing to change specific words (I’m including examples below the code)
Basic scraping demo with “foreach” parsing
Basic scraping demo with “regex” parsing
Basic scraping demo with “foreach” and “regex” parsing
And the example, which presents the same information in a new way…
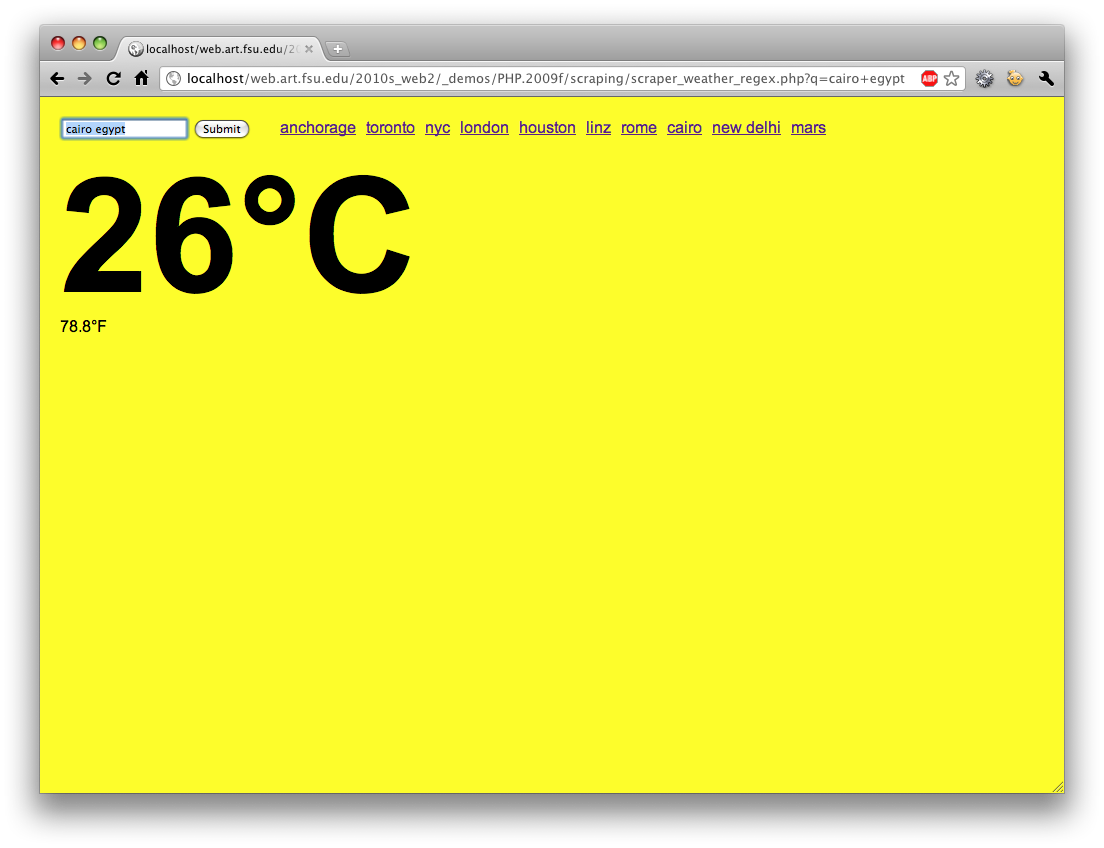
Advanced scraping demo with “regex” parsing. Retrieves current weather in any city and colors the background accordingly. The math below for normalization could use some work.
For the next part of the workshop we used Give Me My Data to export our information from Facebook in order to revisualize it with Nodebox 1.0, a Python IDE similar to Processing.org. Here’s an example:
Update: Some user images from the workshop. Thanks all who joined!
Mutual friends (using Give Me My Data and Graphviz) by Rob Canning
identi.ca network output (starting from my username (claude) with depth 5, rendered to svg with ‘sfdp’ from graphviz) by Claude Heiland-Allen
This “Mutual friends network graph” created with Nodebox using data I exported with Give Me My Data contains 540 “Facebook friends” and their connections to each other. When the graph renders it attempts to position people who have lots of connections closer together. With this you can see groups unfold based on your own social networks. Since I have spent more time in academia than I have at specific jobs my “clusters” are based mostly on my academic history.
You can also see that there are a lot of connections between my high school and where I did my undergraduate study, which is based on the fact they are located very close to each other, so friends from high school also chose the same university or town to live in. There are also a lot of interconnections between Indiana University where I did my undergrad, the University of California, San Diego, where I did graduate study, and Florida State University, where I teach now. This is probably due to the fact that my connections are all within a given field, in my case visual arts, and points to the often expressed notion that “the art world is actually very small.”
Traditional economics operates under fundamental assumptions of scarcity–there’s only so much oil, iron, and gold in the world. But the online economy is built upon three cornerstones: processing power, hard drive storage, and bandwidth–and the costs of all these elements are trending toward zero at an incredible rate.
“The Exploit is that rare thing: a book with a clear grasp of how networks operate that also understands the political implications of this emerging form of power. It cuts through the nonsense about how ‘free’ and ‘democratic’ networks supposedly are, and it offers a rich analysis of how network protocols create a new kind of control. Essential reading for all theorists, artists, activists, techheads, and hackers of the Net.” —McKenzie Wark, author of A Hacker Manifesto
Group Work
by Temporary Services
New York, NY: Printed Matter. 2007
Based on a pamphlet published by Temporary Services in 2002 titled Group Work: A Compilation of Quotes About Collaboration from a Variety of Sources and Practices, this publication provides a multitude of perspectives on the theme of Group Work by practitioners of artistic group practice from 1960s to the present.
Today I launched the public alpha version of my Facebook application Give Me My Data for testing and feedback. This app helps you reclaim and reuse your Facebook data.
Feel free to test it and let me know what you think!
Saturday, August 29, 2009, I will be talking about Keyword Intervention in a paper titled, “Intervention and the Internet: New Forms of Public Practice” at ISEA2009: the 15th International Symposium on Electronic Art in Belfast, Ireland.